Datasets
Data Foundry has several different types of datasets. Here we briefly give an overview. More information on how to use the different datasets in your projects can be found in the use-cases.
General information
You can add all datasets to your projects and for every project you can have 10 or more datasets if you like. Note that you can collect data from different devices in a single dataset (IoT dataset, see below). The same holds for participants and wearables. So, you don't need to create a dataset for every sensor or device.
Meta data
Every dataset needs a name and a description. Try to write something sensible, especially if you want to make the project public. Next, datasets have a start and end date. This allows to open and close the dataset for new data. For example, when you want to schedule an experiment, you can use the start and end dates to ensure that data can be added only in the given time period. If you don't specify start and end dates, then the dataset starts right away and ends in three months.
Public parameters
Data Foundry datasets have an important feature: public parameters. These are three attributes that are present in almost all datasets in Data Foundry, which are derived from the resources that the items are connected to. Ok, that was a bit abstract. Let's go step by step: every project in Data Foundry can have participants, devices and wearables. These are called resources and they can have their own meta-data. For example, if you collect survey data from different participants of a study, you might want to label or tag the participants "experiment" or "control" according to they belong to the experimental group or control group. The two labels, "experiment" and "control", can be captured in a public parameter for every participant. When you collect dat afrom the participant, these data will then be tagged as well with "experiment" or "control", depending on the participant who entered the data.
You can have up to three of these public parameters. for every participant, device, or wearable in your project. If you don't use them, they will just be empty. Why do we do this? We want to avoid accidentally exporting privacy-sensitive participant information with a dataset. Makes sense, right?
Open Participation
Every dataset has a switch "open participation" in the settings (on the "edit" dataset page). This setting has a general meaning and also meaning specific to the different dataset types. Let's start with the general one: "openParticipation" means that data canbe added openly to the dataset. It does NOT mean that the dataset is public or openly readable. TBD.
How to choose the right dataset?
We have made a flow-chart to upport you in getting your project set up with the right datasets. Click on the graphic to enlarge:
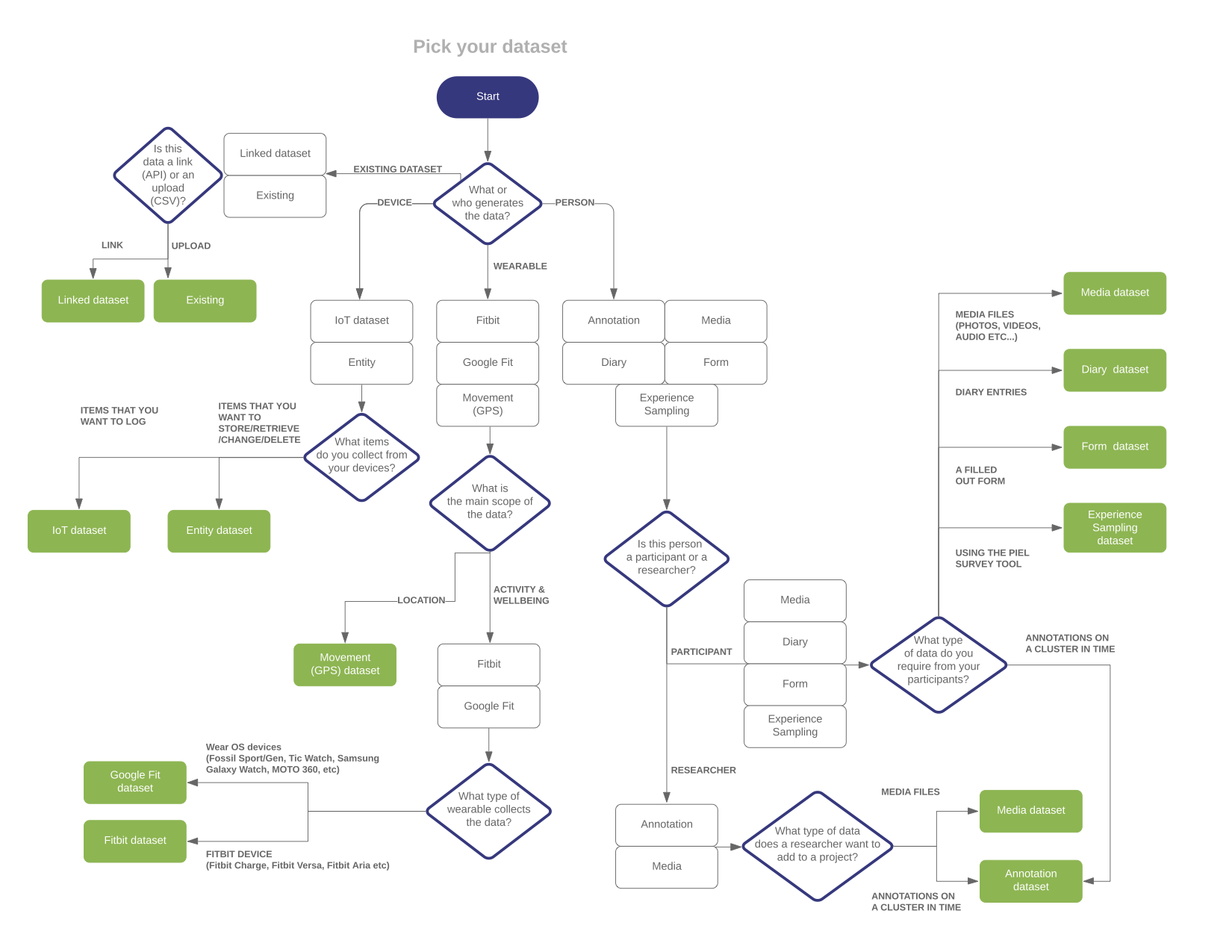
Ok, let's dive into the many different dataset types...
IoT dataset
The IoT dataset type is useful for all kinds of data from sensors and connected products. The items in this dataset are ordered by time, so the first item to be stored is the first in the list, then the next until the most recent time that was stored. Think of a log book in which all items are listed one after each other.
How to get data into this dataset? Check out the smart things use-case.
Entity dataset
The Entity dataset type is useful for storing items that you want to update or even delete at a later point. Every item is identified by an ID and you can protect it with a token against unauthorized access. This way you could use this dataset to build a user account system in your digital prototype, or store visitor information in a museum exhibition. You can also use this dataset to temporarily store data that are shared between different prototypes.
How to get data into this dataset? Check out the sleeping beauties use-case.
Text-based dataset types
Data Foundry offers different dataset types that allow for text entry. Forms are structured and not specific to participants in a project, diary entries and annotations are participant-specific short unstructured text datasets.
Form dataset
The Form dataset type is great for sending quick surveys to a number of people. You can have several different items in a form, from single and multi-select items to text inputs, continuous numerical sliders and grids. The creation of such forms is very straight-forward, just copy your prepared form items into the source box and add the items. There is a preview box next to it that shows how the form will render.
How to get data in this dataset? First create the form, then copy the submission link and send it to your survey participants. Once data is coming in, use the "visualize" button to check out the answers. You can export all data with the "download" button.
Diary dataset
The diary dataset allows to capture qualitative data in a simple textual form from participants about participants of a study. Not only researchers can add this information into the diary dataset, also participants can submit own "diary entries" or annotate media textually.
If you like you can preset a template for a diary dataset. This template will be shown as a placeholder for the text input and this can help remind participants, for example, about the aspects of their experience that you are most interested in or about the desired structure of how they should go through their thoughts and memories. The template can be configured in the configuration section of any diary-type dataset.
We are using the Diary dataset in the object ethnography use case.
Annotation dataset
Annotations are textual bits of data from the researcher's perspective, and annotations refer to clusters in your project. The annotation dataset allows to capture annotations in various forms of groupings of such project resources. Every annotation contains a title and text, as well as a timestamp. The first step to annotations is to create an annotation dataset and then either use one of three options to create annotations:
- Go to the annotation dataset page and use the annotation button
- Go to the "manage resources" page and annotate any cluster that is shown there
- Use the data tool together with a media dataset
Wearable dataset types
The wearable dataset types require connected wearables in your project. Wearables are project resources which you can setup and configure in the "manage resources" page of your project.
Wearables collect data and deliver this data to a third-party store, for example, Fitbit or GoogleFit. At this moment, we only support these two ecosystems with two dataset types. When you create a wearable, you need to choose which ecosystem you want to connect to and then perform a short connection sequence. After that, our Data Foundry server can connect and retrieve your logged wearable data. Both Fitbit and GoogleFit datasets work in the same way, they collect new data from the Fitbit or Google server once per day and import this data as a timeseries that can be visualised, combined with other datasets or exported.
Fitbit dataset
Fitbit data is collected directly from the Fitbit servers. When you set up participants and wearables in Data Foundry, the Data Foundry server will request authorization of the following scopes from the Fitbit server. This happens only once, when participant sign-up their Fitbit wearable to the Data Foundry. Data in the different scopes will be collected either by minute or by day, see the following list:
- Recording by minute:
- Steps -- counting steps
- Distance -- counting moving distance (by steps)
- Floors -- counting the climbt stairs
- Elevation -- counting the height of climbing (by floors)
- Calories -- counting the calories burned every minute
- Heart Rate -- recording heart rate every minute
- Sleep -- recording the status by minute during sleeping
- Activity (Summary) -- summary of all activities in a day
- Recording by day:
- Weight -- recording the weight
- Fat -- recording the fat
- BMI -- recording the BMI
We always request for all the scopes, but only the data for the scopes required by the Fitbit dataset will be stored by the Data Foundry server. The data is collected from Fitbit server once a day and ready for your use-case directly after.
Not all the data of the scopes mentioned above can be obtained by the wearable directly, i.e., Weight, Fat, and BMI. Data for these scopes can only be provided by other smart devices, such as a smart scale or a smart phone app.
GoogleFit
In the GoogleFit dataset, the Data Foundry server will request authorization for the following scopes from the GoogleFit servers. This happens when participants sign-up their GoogleFit wearables to the Data Foundry:
- Recording by minute:
- Activity -- activites by minute
- Calories -- calories burned by minute
- Speed -- moving speed by minute
- Heart rate -- recording the heart rate by minute
- Step count -- recording the steps by minute
- Distance -- counting the distance by minute
- Recording by day:
- Weight -- recording weight once a day
The data collected by and from Google Fit is similar to Fitbit data. The main difference is the scope "Speed", which the GoogleFit API provides for recording moving behavior. We always request for all the scopes, but only the data for the scopes required by the Google Fit dataset will be stored by the Data Foundry server. The data is collected from Fitbit server once a day and ready for your use-case directly after.
Again similar to Fitbit, the "Weight" scope can only be provided by other smart devices, for example, a smart scale.
For participants with Apple Watch x iPhone: They can download the "Google Fit" app, and login, then they can set the permissions in Apple Health to share data with Google Fit app. To do so, these participants can use Apple Watch as their "Google" wearable and record data into the GoogleFit dataset.
File-based dataset types
File-based datasets basically allow you to upload files and store them. While the "existing" and "media" dataset types only store files, the "movement" and "experience sampling" datasets process the files to extract timeseries data. Let's start with the first two:
Existing dataset
The existing dataset basically stores complete, immutable datasets, as structured text or image files. Files in such a dataset are accessible to the project owner, collaborators and subscribers. If the project is a public project, then the files will also be accessible to guests.
Project website. You can use the existing dataset also to host a project website for your project. How to this? Just name the dataset "www" and upload your HTML, JS, CSS and image files into the dataset. If you go back to the project page, you will see a link "Project website" next to the project title. Click this link to see the project website. Note that the project needs to be public to show the project website.
Media dataset
The media dataset stores image files (no video or audio files at this moment), and it allows to annotate the images as well when you go to the dataset page (right side of image entry). You can also show the images in the data tool to visualise, annotate, or export them.
Movement dataset
The movement dataset accepts GPX or XML files, which you can obtain, for example, from wearable GPS trackers. The dataset will try to import the movement data from each uploaded file into a timeseries dataset. If you follow the GPX format it should work fine.
Experience sampling dataset
The experience sampling dataset accepts CSV files that are generated by the PIEL survey app, which is available for iOS and Android devices. The PIEL system supports experience sampling studies with notifications and scheduling. Participants in such a study will send their resulting CSV files to you and you can upload the files to the experience sampling dataset. The dataset imports PIEL-generated files as a timeseries to allow for visualisation and combination with other dataset types.
Linked dataset
The linked dataset is a very simple one: it allows to store a link to a dataset stored in a different location. This is useful for curating different related datasets into a group, or as a bookmark list for further research.