About Data Foundry
When designing intelligent interactive products, when researching user behavior and choices, when investigating the interplay of design and the Everyday, we are in need of data. Traditionally, data in design has been scarce. It was collected either in highly qualitative forms or the means to scale were lacking. Data, if it is collected at all, is silo'ed, that means, it is stored and processed in proprietary ways that are not open to other designers and a community of design students, educators and researchers (Funk, Chiang, & van der Born, 2019).
With data foundry, we aim to change this. We want to scale up data collection and processing, we want to make it extremely easy to connect to various data sources and combine all data into a common format that encourages new forms of design research, mashing up and creative inquiry beyond the low-scale qualitative.
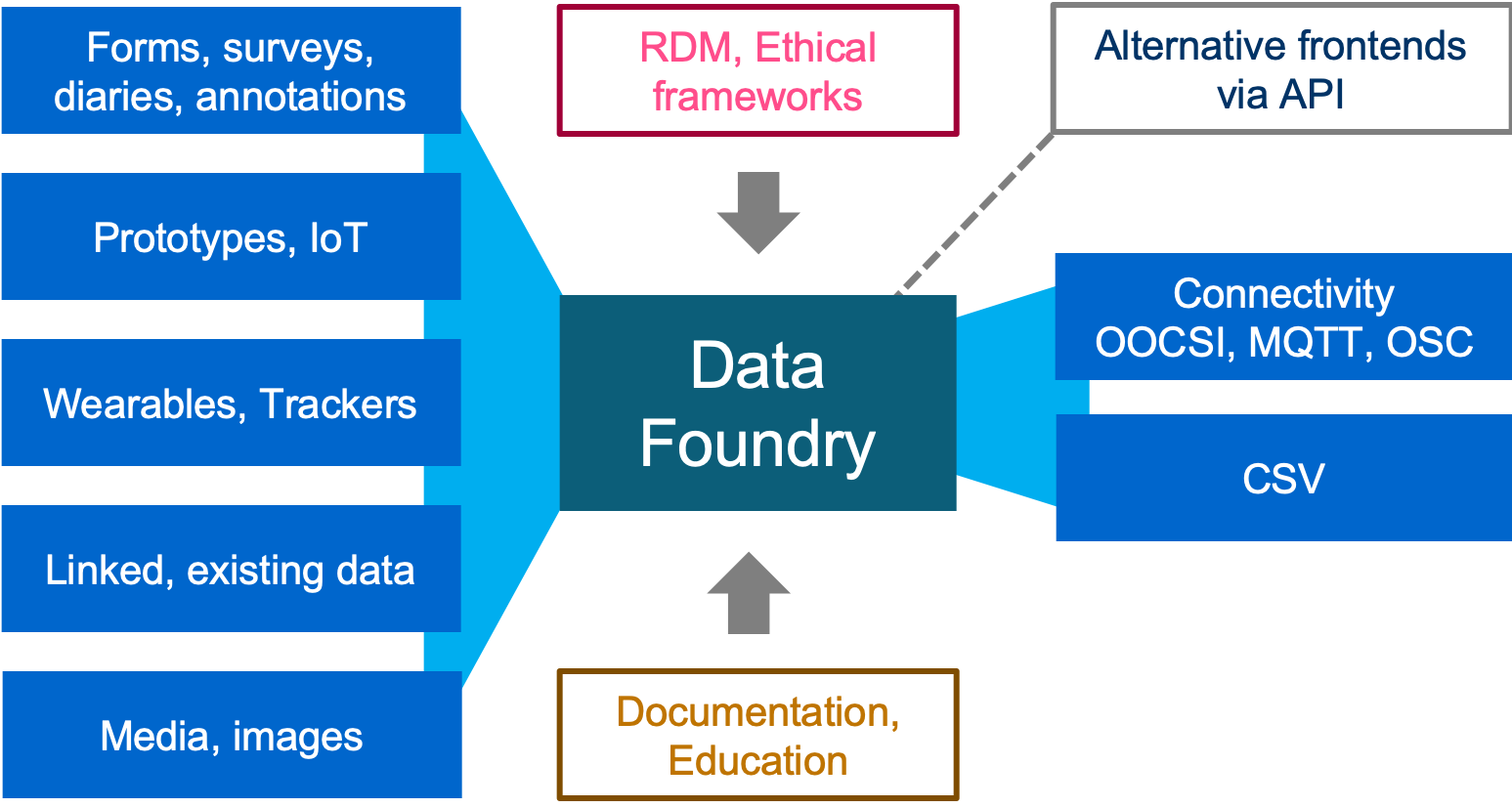
Requirements
A survey among staff, students and alumni of the Industrial Design department at the end of 2018 revealed a diversity of data-related research projects, a variety of commonly used tools, and explicit difficulties in basic data collection, processing, and storage tasks. In addition, new TU/e wide regulations on ethics and data management increase the burden on staff and students to perform design research. In designing the data infrastructure, we aimed for the following primary requirements:
- Enable data collection from various sources
- Collect data in a unified structure (simple, meta-data)
- Provide data access compliant with GDPR
- Provide tools to connect, curate, and share data
- Promote understanding and reuse of data
When focusing on data and technology, two aspects are easy to neglect: the embedding of the data infrastructure in a context of learning and working with it. The former entails educating both staff and students about ways to work with data and to achieve results. The latter concerns the legal and ethical frameworks present and mandated.
Implementation
The implementation of the ID data infrastructure began in February 2019, led an alpha release in late April and a beta release in late October 2019. The core infrastructure is implemented in Java, Scala and JavaScript using the Play! Framework (actor-based architecture), with a database layer for administration and a decoupled layer for storing collected data. The infrastructure has an API layer that allows to build domain or content-specific frontends (a form of "white-labeling").
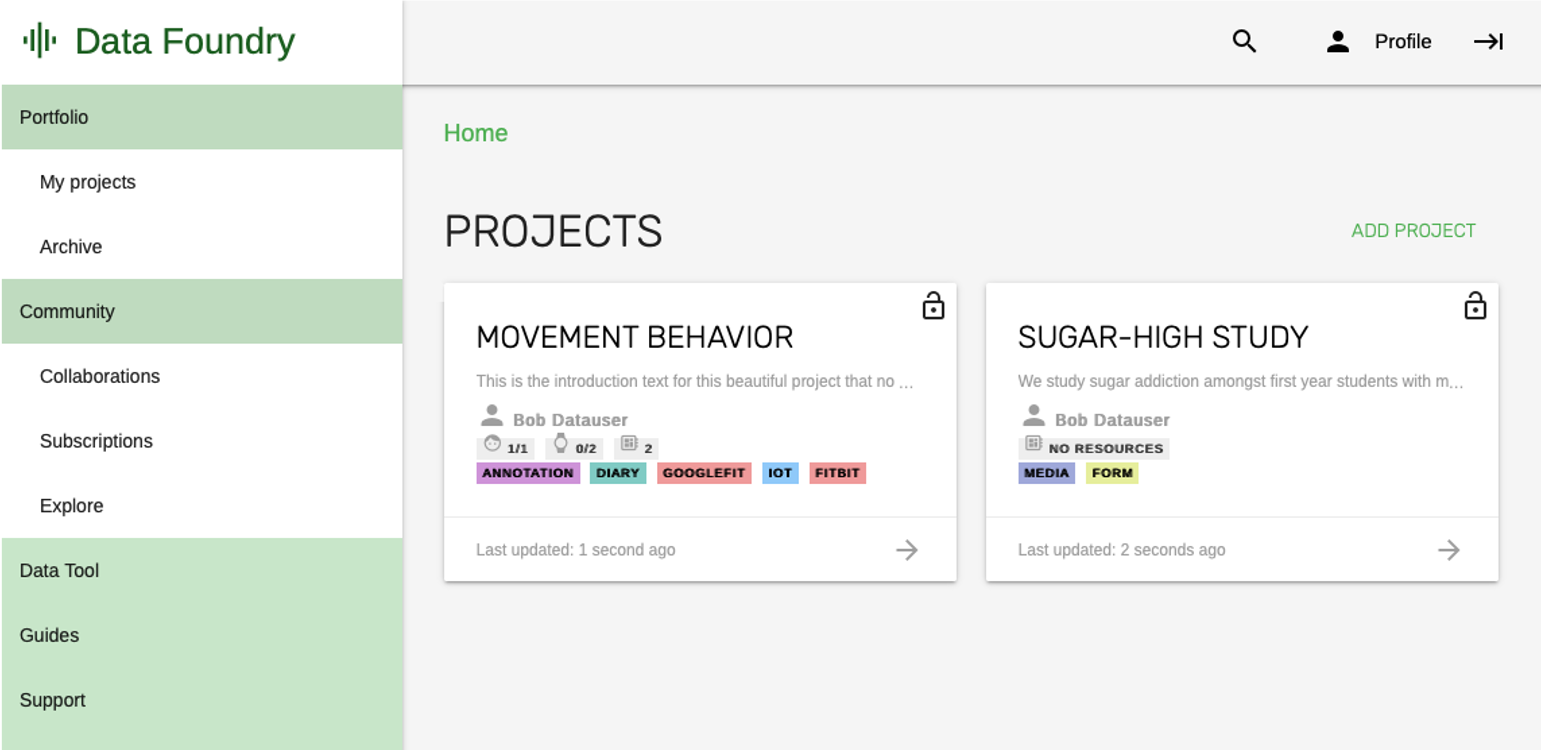
The ID data structure has been piloted in the "Data-enabled Design" Master course in April/May 2019 and we showed how students were able to collect over 1m data items with little prior knowledge and support. The infrastructure has also been used in further courses and design projects since June 2019. It is part of the curriculum of present and upcoming ID courses on data, sensors and AI/ML.
Future steps
Although there are still infrastructure components that need to take the test of time, there are several aspects of data-driven or data-enabled design research that need support: the bi-directional interfacing with the context , i.e., participants, prototypes and their environments, the learning and modeling of data, and the systemic use of collected and generated data through the infrastructure.
Please let us know if you are interested in using Data Foundry for non-academic projects or a different organization; we are to support this as well.
Publications
Funk, M., Chiang, I., & van der Born, E. J. (2019). Data Foundry: A Data Infrastructure for Design Research (p. 1). Retrieved from https://www.tue.nl/en/research/research-areas/data-science/data-science-summit-2019/